Meilisearch as documentation retrieval generator
This document demonstrates how to use Meilisearch as document storage for a simplified RAG (Retrieval-Augmented Generation) system.
How it works
- Documents are stored in Meilisearch as a searchable index
- LiveHelperChat searches using AI-generated queries. The AI extracts important keywords before performing the Meilisearch query
- The LLM generates responses based on the retrieved context from relevant documents
🛠️ Setup
🔌 REST API Configuration
- In this example, we'll use the Gemini streaming version - REST API. Don't forget to change
YOUR_API_KEY - MeiliSearch REST API configuration - REST API. Don't forget to change
MEILI_API_KEY
🤖 Bot Configuration
- Import the MeiliSearch bot configuration - Bot JSON. When importing the bot, choose
GeminiStream
⚠️ Important: After importing the bot, you must manually configure the trigger as shown in the screenshot below, as these settings are not applied automatically on import.
- Rest API:
MeiliSearch- Method:
Search- Execute trigger for [Success]:
MeiliAnswer
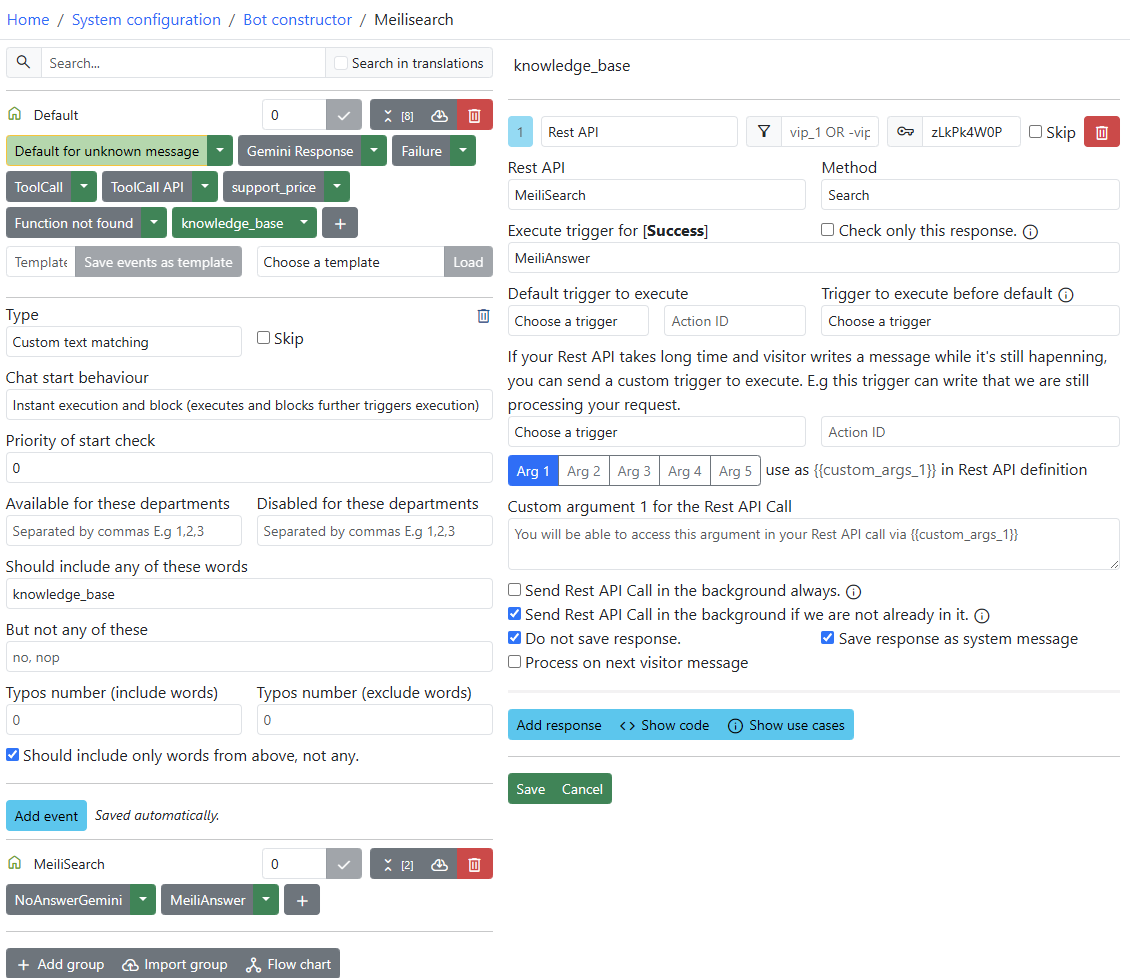
ධ Running Meilisearch
Create a docker-compose.yml file with the following content:
version: '3'
services:
meilisearch:
image: getmeili/meilisearch:latest
ports:
- "7700:7700"
volumes:
- ./meili_data:/meili_data
environment:
MEILI_API_KEY: "xxxxxxxxxxxxxxxxxxxx"
MEILI_MASTER_KEY: "xxxxxxxxxxxxxxxxxxxx"
MEILI_ENV: "production"
restart: unless-stopped
Run the container with:
docker-compose -f docker-compose.yml up -d
💾 Storing documents in Meilisearch
In this example, I'll be using a generated markdown file from https://github.com/LiveHelperChat/crawler-to-md
Sample PHP script command:
⚠️ Note: In the command below,
MEILI_API_KEYshould be replaced with theMEILI_MASTER_KEYfrom yourdocker-compose.ymlfile.
cd /meili && /usr/bin/php ./command.php MEILI_API_KEY lhc_doc /path/to/output/doc_livehelperchat_com/httpsdoc.livehelperchat.com.md
Script content:
<?php
/**
* Meilisearch document indexer script (PHP version)
* Usage: php command.php <master_key> <index_name> <path_to_md_file>
*/
// Check if all required arguments are provided
if ($argc !== 4) {
echo "Usage: php {$argv[0]} <master_key> <index_name> <path_to_md_file>\n";
echo "Example: php {$argv[0]} your_master_key lhc_docs ./sample.md\n";
exit(1);
}
$masterKey = $argv[1];
$indexName = $argv[2];
$mdFilePath = $argv[3];
$meilisearchUrl = "http://localhost:7700";
// Check if the markdown file exists
if (!file_exists($mdFilePath)) {
echo "Error: File {$mdFilePath} not found!\n";
exit(1);
}
/**
* Extract metadata from HTML comment
*/
function extractMetadata($content) {
$metadata = [
'url' => '',
'title' => '',
'hostname' => '',
'description' => '',
'sitename' => '',
'date' => '',
'filedate' => '',
'categories' => '[]',
'tags' => '[]'
];
// Extract URL
if (preg_match('/URL: (\S+)/', $content, $matches)) {
$metadata['url'] = $matches[1];
}
// Extract title
if (preg_match('/title: (.+)/', $content, $matches)) {
$metadata['title'] = trim($matches[1]);
}
// Extract hostname
if (preg_match('/hostname: (\S+)/', $content, $matches)) {
$metadata['hostname'] = $matches[1];
}
// Extract description
if (preg_match('/description: (.+)/', $content, $matches)) {
$metadata['description'] = trim($matches[1]);
}
// Extract sitename
if (preg_match('/sitename: (\S+)/', $content, $matches)) {
$metadata['sitename'] = $matches[1];
}
// Extract date
if (preg_match('/date: (\S+)/', $content, $matches)) {
$metadata['date'] = $matches[1];
}
// Extract filedate
if (preg_match('/filedate: (\S+)/', $content, $matches)) {
$metadata['filedate'] = $matches[1];
}
// Extract categories
if (preg_match('/categories: (\[.*?\])/', $content, $matches)) {
$metadata['categories'] = $matches[1];
}
// Extract tags
if (preg_match('/tags: (\[.*?\])/', $content, $matches)) {
$metadata['tags'] = $matches[1];
}
return $metadata;
}
/**
* Clean and prepare content
*/
function cleanContent($content) {
// Remove HTML comments and metadata
$content = preg_replace('/^<!--$.+?^-->$/ms', '', $content);
// Remove --- separators
$content = preg_replace('/^---$/m', '', $content);
// Trim leading/trailing whitespace
return trim($content);
}
/**
* Create JSON document
*/
function createJsonDocument($id, $metadata, $content) {
// Validate and decode JSON arrays
$categories = json_decode($metadata['categories']);
$tags = json_decode($metadata['tags']);
if ($categories === null) {
$categories = [];
}
if ($tags === null) {
$tags = [];
}
return [
'id' => $id,
'url' => $metadata['url'],
'title' => $metadata['title'],
'hostname' => $metadata['hostname'],
'description' => $metadata['description'],
'sitename' => $metadata['sitename'],
'date' => $metadata['date'],
'filedate' => $metadata['filedate'],
'categories' => $categories,
'tags' => $tags,
'content' => $content
];
}
/**
* Make HTTP request to Meilisearch
*/
function makeRequest($url, $method, $data = null, $masterKey = '') {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, $method);
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Authorization: Bearer ' . $masterKey,
'Content-Type: application/json'
]);
if ($data !== null) {
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
}
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
return ['response' => $response, 'http_code' => $httpCode];
}
echo "Starting document indexing process...\n";
echo "Meilisearch URL: {$meilisearchUrl}\n";
echo "Index: {$indexName}\n";
echo "File: {$mdFilePath}\n";
// Create index if it doesn't exist
echo "Creating/updating index...\n";
$indexData = [
'uid' => $indexName,
'primaryKey' => 'id'
];
makeRequest("{$meilisearchUrl}/indexes", 'POST', $indexData, $masterKey);
// Configure searchable attributes
echo "Configuring searchable attributes...\n";
$searchableAttributes = ['title', 'content', 'description', 'url'];
makeRequest("{$meilisearchUrl}/indexes/{$indexName}/settings/searchable-attributes", 'PUT', $searchableAttributes, $masterKey);
// Configure filterable attributes
echo "Configuring filterable attributes...\n";
$filterableAttributes = ['hostname', 'sitename', 'date', 'filedate', 'categories', 'tags'];
makeRequest("{$meilisearchUrl}/indexes/{$indexName}/settings/filterable-attributes", 'PUT', $filterableAttributes, $masterKey);
// Read the entire file
echo "Processing documents...\n";
$fileContent = file_get_contents($mdFilePath);
// Create temporary directory for processing
$scriptDir = dirname(__FILE__);
$tempDir = $scriptDir . '/temp_docs_php';
if (!is_dir($tempDir)) {
mkdir($tempDir, 0755, true);
}
// Split the file by HTML comments
$documents = [];
$parts = preg_split('/^<!--$/m', $fileContent);
foreach ($parts as $index => $part) {
if ($index === 0) continue; // Skip the part before the first comment
// Find the end of the comment and the content
if (preg_match('/^(.+?)^-->(.*)$/ms', $part, $matches)) {
$comment = '<!--' . $matches[1] . '-->';
$content = $comment . $matches[2];
$documents[] = $content;
}
}
// Process each document
$docCount = 0;
$batchDocs = [];
$batchSize = 10;
$currentDocIds = []; // Track current document IDs
foreach ($documents as $docIndex => $docContent) {
echo "Processing document " . ($docIndex + 1) . "\n";
// Extract metadata
$metadata = extractMetadata($docContent);
// Skip if no URL (invalid document)
if (empty($metadata['url'])) {
echo "Skipping document with no URL\n";
continue;
}
// Clean content
$cleanContent = cleanContent($docContent);
// Generate unique ID from URL
$docId = preg_replace('/[^a-zA-Z0-9]/', '_', $metadata['url']);
$docId = preg_replace('/_+/', '_', $docId);
$docId = trim($docId, '_');
// Track this document ID
$currentDocIds[] = $docId;
// Create JSON document
try {
$jsonDoc = createJsonDocument($docId, $metadata, $cleanContent);
$batchDocs[] = $jsonDoc;
$docCount++;
// Send batch every 10 documents or if this is the last document
if (count($batchDocs) >= $batchSize || $docIndex === count($documents) - 1) {
echo "Sending batch of " . count($batchDocs) . " documents to Meilisearch...\n";
$result = makeRequest("{$meilisearchUrl}/indexes/{$indexName}/documents", 'POST', $batchDocs, $masterKey);
echo "Response: " . $result['response'] . "\n";
// Reset batch
$batchDocs = [];
}
} catch (Exception $e) {
echo "Error processing document: " . $e->getMessage() . "\n";
continue;
}
}
echo "Document indexing completed!\n";
echo "Total documents processed: {$docCount}\n";
echo "Index: {$indexName}\n";
// Remove old documents that no longer exist
echo "Checking for old documents to remove...\n";
$allDocsResult = makeRequest("{$meilisearchUrl}/indexes/{$indexName}/documents?limit=10000", 'GET', null, $masterKey);
if ($allDocsResult['http_code'] === 200) {
$allDocsResponse = json_decode($allDocsResult['response'], true);
$existingDocs = $allDocsResponse['results'] ?? [];
$docsToDelete = [];
foreach ($existingDocs as $doc) {
if (!in_array($doc['id'], $currentDocIds)) {
$docsToDelete[] = $doc['id'];
}
}
if (!empty($docsToDelete)) {
echo "Removing " . count($docsToDelete) . " old documents...\n";
$deleteResult = makeRequest("{$meilisearchUrl}/indexes/{$indexName}/documents/delete-batch", 'POST', $docsToDelete, $masterKey);
echo "Delete response: " . $deleteResult['response'] . "\n";
} else {
echo "No old documents to remove.\n";
}
} else {
echo "Warning: Could not retrieve existing documents for cleanup.\n";
}
// Get index stats
echo "Getting index statistics...\n";
$statsResult = makeRequest("{$meilisearchUrl}/indexes/{$indexName}/stats", 'GET', null, $masterKey);
$stats = json_decode($statsResult['response'], true);
echo json_encode($stats, JSON_PRETTY_PRINT) . "\n";
// Clean up temporary directory
if (is_dir($tempDir)) {
$files = glob($tempDir . '/*');
foreach ($files as $file) {
if (is_file($file)) {
unlink($file);
}
}
rmdir($tempDir);
}
?>